Building a Write-ahead Log in Go
Continuing our series on building a database storage engine from scratch, in today's article we'll explore the concept of write-ahead logging. The write-ahead log (WAL) is a mechanism used in database management systems to ensure data durability and recoverability. It complements memtables by providing a reliable and efficient way to persist data changes before they are transferred to disk for long term storage in the form of SSTables.
In this tutorial, we'll explore how to implement a simple write-ahead log in Go, building upon the code we developed previously when we looked into the internals of memtables and SSTables. We'll cover the basics of write-ahead logs, such as how they work and why they are important. Additionally, we'll see how WALs integrate with all the other components of a database storage engine to provide a robust and reliable solution for data persistence and recovery.
Without further ado, let's get started!
Understanding WALs
As you probably remember from our previous discussions, when you perform a DML operation against the database, the storage engine first records all of the resulting changes into a data structure called a memtable. Data stored inside a memtable (as the name implies) only resides in memory, and no data is immediately changed on disk.
Once the memtable reaches a certain size, the storage engine marks it as immutable and begins writing changes to a new memtable. This process is called a rotation. Rotations generate an increasing amount of immutable memtables in the storage engine, which, beyond a certain threshold, causes the storage engine to trigger a flush operation.
During a flush operation, the storage engine goes through all of the immutable memtables and converts them to SSTables (i.e., stores them on disk as *.sst files). It then expels them from memory to make room for new memtables to be created. Once inside an SSTable, stored data can be considered durable and safe, as the storage engine can easily retrieve it from the disk even after a system restart.
If, however, the system crashes abruptly, any data stored inside memtables that hasn't been copied to disk will be permanently lost. This is the exact problem that write-ahead logs are designed to solve.
A write-ahead log is basically an additional file on disk that records DML operations before they are applied to the active memtable. This ensures that in case of an unexpected crash, all DML operations can be replayed from the write-ahead log, allowing the memtable to be rebuilt when the database system is restarted.
You might wonder, then, what's the point of maintaining a separate WAL file for each memtable if potential data loss is such a big problem, rather than writing changes directly to disk? That's a good question!
Remember that data is stored on disk in SSTables. SSTables use a specialized binary format that's designed to utilize disk storage as efficiently as possible by employing techniques such as incremental encoding and data compression to maximize the amount of data that can be stored within a single physical block on disk. Furthermore, data within SSTables is organized in a way that facilitates quick and efficient searching while requiring a minimal amount of disk access operations.
These characteristics make it really difficult to place data directly on disk without violating the invariants of the *.sst file format. In other words, if you want to record a DML operation directly into an SSTable, you pretty much have to rebuild and rewrite the entire SSTable on disk if you want to maintain its invariants. The same applies if you try to serialize memtable representations on disk. Memtables are efficient as in-memory data structures, but just a small change in the data caused by a DML operation can lead to a significant amount of rewriting for a memtable representation serialized on disk.
The write-ahead log, thus, provides some middle ground. The WAL records all DML operations in the order of their occurrence without directly getting involved in serving reads or performing updates over memtables. It uses a plain and simple format, primarily optimized for sequential reading and writing, with the sole objective of providing an efficient mechanism for reconstructing a memtable.
We'll specify a file format for our write-ahead log in the next section.
Defining a WAL File Format
Before generating our first WAL file, we must settle on its format. The main goal is to structure the write-ahead log in a way that minimizes the number of disk access operations required for retrieving all of the recorded data while also making it easy to append new data to its tail.
The WAL file can therefore be organized as a series of fixed-size data blocks, where the size of each data block is either equal to or a multiple of the physical block size of the underlying storage device (i.e., the smallest unit that can be read from the given HDD or SSD device):

Each data block hosts one or more WAL records, where each WAL record essentially represents a DML operation requested for execution against the database storage engine.
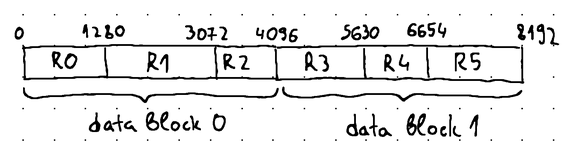
WAL records may have a varying length, as they need to include both the key and the value corresponding to the requested DML operation. Therefore, a data block can rarely fill up entirely without either the last WAL record crossing its boundary or some empty space remaining at its tail. In such cases, we prefer to fill up the empty space with zeros and place the WAL record in the next data block:
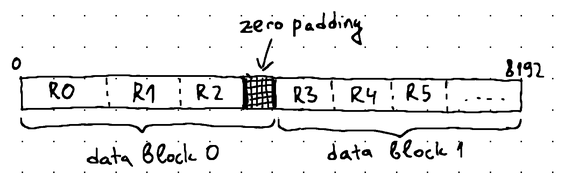
We don't allow the record to cross the data block boundary, because the entire purpose of the data block structure is to enable reading and processing the WAL file one block at a time. If a record spreads across multiple blocks, it will be impossible to process it without loading all of the blocks that it occupies into memory:
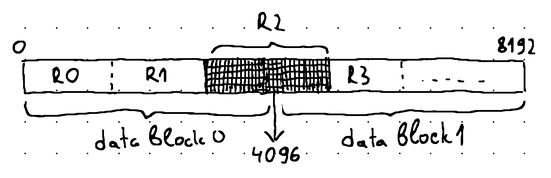
Inevitably, real-world databases have to deal with records exceeding the specified data block size. In such cases, storage engines usually apply a technique known as chunking. Chunking enables a WAL record to be split into multiple smaller chunks. These chunks are then distributed across the available data blocks inside the WAL file, but each chunk is essentially a WAL record that can be processed on its own without having to load the data blocks containing its sibling chunks in advance:
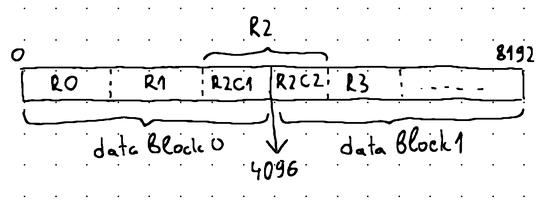
Assuming that our records are sufficiently small to never exceed the specified data block size, we'll create an initial implementation that doesn't support chunking to keep things simple. However, towards the end of the article, we'll build upon this initial implementation and demonstrate how chunking can be implemented too.
We'll use the following format to represent a WAL record:
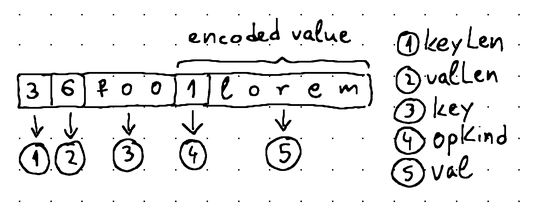
This format is pretty much identical to how we used to represent data in one of our initial SSTable implementations. In the next section, we'll see how we can write these records to an actual WAL file.
Creating WAL Files
Writing records to a WAL file requires creating that WAL file first. The component in our storage engine responsible for creating new files on disk is the storage provider (./storage/provider.go). Up until now, the storage provider only worked with *.sst files, so we'll have to modify it a little bit to also support write-ahead logs.
We'll first register a new FileType constant to indicate that a file could be of type WAL:
. . .
type FileType int
const (
FileTypeUnknown FileType = iota
FileTypeSSTable
FileTypeWAL
)
. . ../storage/provider.go
We'll also define a new FileMetadata method named IsWAL, making it easier to determine whether we're working with a write-ahead log file or some other file type:
. . .
type FileMetadata struct {
fileNum int
fileType FileType
}
func (f *FileMetadata) IsSSTable() bool {
return f.fileType == FileTypeSSTable
}
func (f *FileMetadata) IsWAL() bool {
return f.fileType == FileTypeWAL
}
. . ../storage/provider.go
We'll make the PrepareNewFile method private and abstract it away by introducing two more specialized public methods named PrepareNewSSTFile and PrepareNewWALFile that allow us to request specific file types:
. . .
func (s *Provider) prepareNewFile(fileType FileType) *FileMetadata {
return &FileMetadata{
fileNum: s.nextFileNum(),
fileType: fileType,
}
}
func (s *Provider) PrepareNewSSTFile() *FileMetadata {
return s.prepareNewFile(FileTypeSSTable)
}
func (s *Provider) PrepareNewWALFile() *FileMetadata {
return s.prepareNewFile(FileTypeWAL)
}
. . ../storage/provider.go
We'll also change the makeFileName method to accept an additional fileType argument, which will allow us to create file names with distinct file extensions (*.log for write-ahead logs and *.sst for SSTables):
. . .
func (s *Provider) makeFileName(fileNumber int, fileType FileType) string {
switch fileType {
case FileTypeSSTable:
return fmt.Sprintf("%06d.sst", fileNumber)
case FileTypeWAL:
return fmt.Sprintf("%06d.log", fileNumber)
case FileTypeUnknown:
}
panic("unknown file type")
}
. . ../storage/provider.go
Finally, we'll have the OpenFileForWriting and OpenFileForReading methods use the updated makeFileName method with the corresponding fileType passed in, so we can open new write-ahead logs for both reading and writing:
. . .
func (s *Provider) OpenFileForWriting(meta *FileMetadata) (*os.File, error) {
const openFlags = os.O_RDWR | os.O_CREATE | os.O_EXCL
filename := s.makeFileName(meta.fileNum, meta.fileType)
file, err := os.OpenFile(filepath.Join(s.dataDir, filename), openFlags, 0644)
if err != nil {
return nil, err
}
return file, nil
}
func (s *Provider) OpenFileForReading(meta *FileMetadata) (*os.File, error) {
const openFlags = os.O_RDONLY
filename := s.makeFileName(meta.fileNum, meta.fileType)
file, err := os.OpenFile(filepath.Join(s.dataDir, filename), openFlags, 0)
if err != nil {
return nil, err
}
return file, nil
}
. . ../storage/provider.go
With that, the storage provider is fully prepared for creating new WAL files.
These changes also have to be reflected in the flushMemtables method of our main DB structure, where we should change the storage provider method call from PrepareNewFile to PrepareNewSSTFile:
. . .
func (d *DB) flushMemtables() error {
n := len(d.memtables.queue) - 1
flushable := d.memtables.queue[:n]
d.memtables.queue = d.memtables.queue[n:]
for i := 0; i < len(flushable); i++ {
meta := d.dataStorage.PrepareNewSSTFile()
f, err := d.dataStorage.OpenFileForWriting(meta)
if err != nil {
return err
}
w := sstable.NewWriter(f)
err = w.Process(flushable[i])
if err != nil {
return err
}
err = w.Close()
if err != nil {
return err
}
d.sstables = append(d.sstables, meta)
}
return nil
}
. . ../db.go
So far, so good. We can now use the updated storage provider implementation to define a new method for creating WAL files inside our main DB structure:
. . .
func (d *DB) createNewWAL() error {
ds := d.dataStorage
fm := ds.PrepareNewWALFile()
logFile, err := ds.OpenFileForWriting(fm)
if err != nil {
return err
}
// TODO: do something with the returned `logFile`
return nil
}
. . ../db.go
The idea is to call createNewWAL during database initialization, right before any memtables are created:
. . .
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
err = db.loadSSTables()
if err != nil {
return nil, err
}
if err = db.createNewWAL(); err != nil {
return nil, err
}
db.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
db.memtables.queue = append(db.memtables.queue, db.memtables.mutable)
return db, nil
}
. . . ./db.go
The writing itself can be delegated to a separate structure that's in charge of assembling data blocks in memory before writing them out to the newly created WAL file. We'll call this structure the WAL Writer:
package wal
import "io"
type Writer struct {
file io.Writer
}
func NewWriter(logFile io.Writer) *Writer {
w := &Writer{
file: logFile,
}
return w
}
./wal/writer.go
There should always be only one active WAL file at a time. To let our main DB structure interact with that file, we can define a new field storing a reference to its corresponding Writer:
. . .
type DB struct {
dataStorage *storage.Provider
memtables struct {
mutable *memtable.Memtable
queue []*memtable.Memtable
}
wal struct {
w *wal.Writer
}
sstables []*storage.FileMetadata
}
. . ../db.go
We can then update the createNewWAL method to initialize a new Writer instance and store its reference into the newly introduced db.wal.w field:
. . .
func (d *DB) createNewWAL() error {
ds := d.dataStorage
fm := ds.PrepareNewWALFile()
logFile, err := ds.OpenFileForWriting(fm)
if err != nil {
return err
}
d.wal.w = wal.NewWriter(logFile)
return nil
}
. . ../db.go
With that, we have an empty WAL file ready for writing. Let's see how to implement its Writer in the next section.
Writing to WAL Files
Earlier, we settled on the following format for our log records:
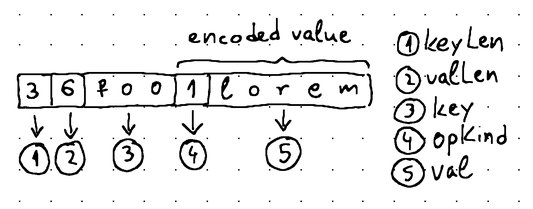
Our Writer should place records like these into fixed-size data blocks and, as they fill up, write these data blocks out to the underlying WAL file.
We can use the following structure to represent a data block:
. . .
const blockSize = 4 << 10 // 4 KiB
type block struct {
buf [blockSize]byte
offset int
len int
}
. . ../wal/writer.go
The buf field holds the actual data stored in the data block, the offset field tracks the current position within the block that data should be written to or read from, and the len field tracks the total size of the data block (some blocks may be shorter than the specified blockSize, but more on that later).
Here, we're settling on a fixed size of 4 KiB for our data blocks, but this is really a matter of testing and experimentation (many storage engines use 32 KiB as the default blockSize).
We can instantiate a new block structure when constructing our Writer to use its buffer as a scratch space for assembling new blocks in memory before writing them out to the underlying write-ahead log:
. . .
type Writer struct {
block *block
file io.Writer
}
func NewWriter(logFile io.Writer) *Writer {
w := &Writer{
block: &block{},
file: logFile,
}
return w
}
. . ../wal/writer.go
The entire procedure of writing a new record to a data block can be expressed with the following code:
. . .
func (w *Writer) record(key, val []byte) error {
// determine the maximum length the WAL record could occupy
keyLen, valLen := len(key), len(val)
maxLen := 2*binary.MaxVarintLen64 + keyLen + valLen
// determine where the WAL record should be positioned
// within the current block
b := w.block
start := b.offset
end := start + maxLen
// seal the block if it doesn't have enough space to accommodate
// the WAL record and start writing to a new block instead
if end > blockSize {
// TODO: seal the block and write out b.buf[b.offset:] to the WAL file
// TODO: prepare new block for writing (b.offset = 0)
start = b.offset
end = start + maxLen
}
// append WAL record to the current block buffer and flush it to disk
buf := b.buf[start:end]
n := binary.PutUvarint(buf[:], uint64(keyLen))
n += binary.PutUvarint(buf[n:], uint64(valLen))
copy(buf[n:], key)
copy(buf[n+keyLen:], val)
dataLen := n + keyLen + valLen
b.offset += dataLen
// TODO: write out buf[:dataLen] to the WAL file
return nil
}
. . ../wal/writer.go
We pass the key and val associated with the requested DML operation to the record method, and it checks whether their representation fits into the current block or whether the block should be sealed (i.e., padded with zeros) and a new one should be started. Then, it puts the binary representation of the WAL record into the block buffer and writes it out to the underlying WAL file.
In the example above, though, the actual methods for sealing and writing data blocks to the WAL file have been substituted with placeholders, so let's implement them.
We can use the following method for writing out the data blocks:
. . .
// writeAndSync writes to the underlying WAL file and
// forces a sync of its contents to stable storage
func (w *Writer) writeAndSync(p []byte) (err error) {
if _, err = w.file.Write(p); err != nil {
return err
}
if err = w.file.Sync(); err != nil {
return err
}
return nil
}
. . ../wal/writer.go
writeAndSync takes in the updated portion of the block buffer (the passed p []byte slice) and writes it to the underlying WAL file. For greater durability, it also forces a sync of its contents to stable storage to ensure that the data is immediately written to disk rather than stuck in the Linux page cache.
Syncing requires certain changes in our Writer, though:
. . .
type syncCloser interface {
io.Writer
Sync() error
}
type Writer struct {
block *block
file syncCloser
}
func NewWriter(logFile syncCloser) *Writer {
w := &Writer{
block: &block{},
file: logFile,
}
return w
}
. . ../wal/writer.go
Sealing the block can then be implemented like this:
. . .
// sealBlock applies zero padding to the current block
// and calls writeAndSync to persist it to stable storage
func (w *Writer) sealBlock() error {
b := w.block
clear(b.buf[b.offset:])
if err := w.writeAndSync(b.buf[b.offset:]); err != nil {
return err
}
b.offset = 0
return nil
}
. . ../wal/writer.go
sealBlock basically zeros out all the bytes in the remaining portion of the block buffer and writes them to the underlying WAL file using writeAndSync. It then resets the offset of the block buffer to 0 to prepare it for the next write operation. The buffer itself remains dirty (holding the contents of the previous data block), but that's okay as only newly modified portions of the buffer are going to be synced to disk during subsequent write operations.
With that, we can finalize the record method as follows:
. . .
func (w *Writer) record(key, val []byte) error {
// determine the maximum length the WAL record could occupy
keyLen, valLen := len(key), len(val)
maxLen := 2*binary.MaxVarintLen64 + keyLen + valLen
// determine where the WAL record should be positioned within the current block
b := w.block
start := b.offset
end := start + maxLen
// seal the block if it doesn't have enough space to accommodate the WAL record and start writing to a new block instead
if end > blockSize {
if err := w.sealBlock(); err != nil {
return err
}
start = b.offset
end = start + maxLen
}
// append WAL record to the current block and flush it to disk
buf := b.buf[start:end]
n := binary.PutUvarint(buf[:], uint64(keyLen))
n += binary.PutUvarint(buf[n:], uint64(valLen))
copy(buf[n:], key)
copy(buf[n+keyLen:], val)
dataLen := n + keyLen + valLen
b.offset += dataLen
if err := w.writeAndSync(buf[:dataLen]); err != nil {
return err
}
return nil
}
. . ../wal/writer.go
The only thing left now is to hook the record method to our main DB structure, calling it right before we apply a DML operation to the active memtable:
. . .
func (d *DB) Set(key, val []byte) {
// TODO: record insertion into WAL file
m := d.prepMemtableForKV(key, val)
m.Insert(key, val)
d.maybeScheduleFlush()
}
func (d *DB) Delete(key []byte) {
// TODO: record deletion into WAL file
m := d.prepMemtableForKV(key, nil)
m.InsertTombstone(key)
d.maybeScheduleFlush()
}
. . . ./db.go
To pass information about the type of DML operation (insertion or deletion), we introduce two specialized public methods (RecordInsertion and RecordDeletion) in our Writer, abstracting away the more generic record method as follows:
. . .
func (w *Writer) RecordInsertion(key, val []byte) error {
val = w.encoder.Encode(encoder.OpKindSet, val)
return w.record(key, val)
}
func (w *Writer) RecordDeletion(key []byte) error {
val := w.encoder.Encode(encoder.OpKindDelete, nil)
return w.record(key, val)
}
. . ../wal/writer.go
These two methods make use of our familiar Encoder to embed the DML operation type into the val portion of the WAL record, so we need to reflect this requirement in the Writer structure definition and its associated constructor:
. . .
type Writer struct {
block *block
file syncWriter
encoder *encoder.Encoder
}
func NewWriter(logFile syncWriter) *Writer {
w := &Writer{
block: &block{},
file: logFile,
encoder: encoder.NewEncoder(),
}
return w
}
. . ../wal/writer.go
We can then adjust the Set and Delete methods in our main DB structure to call RecordInsertion and RecordDeletion as follows:
. . .
func (d *DB) Set(key, val []byte) error {
if err := d.wal.w.RecordInsertion(key, val); err != nil {
return err
}
m := d.prepMemtableForKV(key, val)
m.Insert(key, val)
d.maybeScheduleFlush()
return nil
}
func (d *DB) Delete(key []byte) error {
if err := d.wal.w.RecordDeletion(key); err != nil {
return err
}
m := d.prepMemtableForKV(key, nil)
m.InsertTombstone(key)
d.maybeScheduleFlush()
return nil
}
. . . ./db.go
Now, every DML operation will lead to a WAL record being written to the WAL file before any memtables are modified.
Rotating WAL Files
Everything looks great so far, but as you remember, space in memtables eventually runs out, so the storage engine rotates them. What happens to the WAL file during a memtable rotation, then?
A WAL file is always tied to a particular memtable, so whenever we rotate a memtable, we should also rotate the WAL file (i.e., we should start writing to a new WAL file). If the rotation triggers a subsequent flush of the memtable, the WAL file has to be deleted from disk, as it's no longer needed for data recovery (that's because the memtable has become an SSTable).
If we're going to be deleting WAL files, we need to define a new method in our Writer to make sure they can be closed as needed:
func (w *Writer) Close() (err error) {
if err = w.sealBlock(); err != nil {
return err
}
err = w.file.Close()
w.file = nil
if err != nil {
return err
}
return nil
}./wal/writer.go
The Close method seals the remaining portion of the data block buffer being prepared in memory, writes it out to the underlying WAL file, and finally closes that file.
This calls for another small change in our Writer:
. . .
type syncWriteCloser interface {
io.WriteCloser
Sync() error
}
type Writer struct {
block *block
file syncWriteCloser
encoder *encoder.Encoder
}
func NewWriter(logFile syncWriteCloser) *Writer {
w := &Writer{
block: &block{},
file: logFile,
encoder: encoder.NewEncoder(),
}
return w
}
. . ../wal/writer.go
To handle the log rotation process, we define the following method in our main DB structure:
func (d *DB) rotateWAL() (err error) {
if err = d.wal.w.Close(); err != nil {
return err
}
if err = d.createNewWAL(); err != nil {
return err
}
return nil
}./db.go
rotateWAL calls the Close method of our Writer and then immediately invokes createNewWAL to create a brand new Writer pointing to a new file. Then, whenever a memtable requires rotation, we can simply call rotateWAL before rotateMemtables to ensure that the new memtable will be backed by a new WAL file.
This requires making the following changes to the prepMemtableForKV method:
. . .
// prepMemtableForKV ensures that the mutable memtable has
// sufficient space to accommodate the insertion of "key" and "val".
func (d *DB) prepMemtableForKV(key, val []byte) (*memtable.Memtable, error) {
m := d.memtables.mutable
if !m.HasRoomForWrite(key, val) {
if err := d.rotateWAL(); err != nil {
return nil, err
}
m = d.rotateMemtables()
}
return m, nil
}
. . . ./db.go
As prepareMemtableForKV could now return an error, this requires adjusting our main Set and Delete methods accordingly:
. . .
func (d *DB) Set(key, val []byte) error {
if err := d.wal.w.RecordInsertion(key, val); err != nil {
return err
}
m, err := d.prepMemtableForKV(key, val)
if err != nil {
return err
}
m.Insert(key, val)
d.maybeScheduleFlush()
return nil
}
func (d *DB) Delete(key []byte) error {
if err := d.wal.w.RecordDeletion(key); err != nil {
return err
}
m, err := d.prepMemtableForKV(key, nil)
if err != nil {
return err
}
m.InsertTombstone(key)
d.maybeScheduleFlush()
return nil
}
. . ../db.go
Now, every time a memtable gets rotated, the corresponding WAL file will get rotated as well. We're not deleting any WAL files yet, though, so it's time to work on this next.
Deleting WAL Files
As you remember from earlier, a WAL file has to be deleted right after its memtable gets flushed to disk as an SSTable. This happens in the flushMemtables method of the main DB structure.
Depending on the size of the memtable queue, the storage engine may sometimes decide to flush multiple memtables at once, so it's important to know which log file corresponds to which memtable. This information is currently not available in our Memtable structures, so we should work on establishing this relationship.
We could do this by using the WAL file metadata returned from each unique PrepareNewWALFile call. This data can be saved in a new field in each corresponding Memtable structure. That would work because the file metadata contains both the file type and the unique file number, so the storage provider could easily use this information to locate the file.
There are currently two places in the code where we're constructing new memtables.
In the rotateMemtables method:
. . .
func (d *DB) rotateMemtables() *memtable.Memtable {
d.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
d.memtables.queue = append(d.memtables.queue, d.memtables.mutable)
return d.memtables.mutable
}
. . ../db.go
And in the Open method:
. . .
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
err = db.loadSSTables()
if err != nil {
return nil, err
}
if err = db.createNewWAL(); err != nil {
return nil, err
}
db.memtables.mutable = memtable.NewMemtable(memtableSizeLimit)
db.memtables.queue = append(db.memtables.queue, db.memtables.mutable)
return db, nil
}
. . . ./db.go
If you look closely, the code for creating a new memtable in the Open method is pretty much identical to the one in rotateMemtable, so let's consolidate it by refactoring Open to call rotateMemtable directly:
. . .
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
if err = db.loadFiles(); err != nil {
return nil, err
}
if err = db.createNewWAL(); err != nil {
return nil, err
}
db.rotateMemtables()
return db, nil
}
. . ../db.go
We can then modify our Memtable structure as follows to allow for storing the log file metadata:
. . .
type Memtable struct {
sl *skiplist.SkipList
sizeUsed int // The approximate amount of space used by the Memtable so far (in bytes).
sizeLimit int // The maximum allowed size of the Memtable (in bytes).
encoder *encoder.Encoder
logMeta *storage.FileMetadata
}
func NewMemtable(sizeLimit int, logMeta *storage.FileMetadata) *Memtable {
m := &Memtable{
sl: skiplist.NewSkipList(),
sizeLimit: sizeLimit,
encoder: encoder.NewEncoder(),
logMeta: logMeta,
}
return m
}
. . . ./memtable/memtable.go
So far, in createNewWAL, we've been passing the file metadata returned from PrepareNewWALFile directly to OpenFileForWriting without storing it anywhere in our main DB structure, making it hard to reference it from the rotateMemtables method.
Let's tweak our DB structure a little bit to begin storing this information in a new field:
. . .
type DB struct {
dataStorage *storage.Provider
memtables struct {
mutable *memtable.Memtable
queue []*memtable.Memtable
}
wal struct {
w *wal.Writer
fm *storage.FileMetadata
}
sstables []*storage.FileMetadata
}
. . .
func (d *DB) createNewWAL() error {
ds := d.dataStorage
fm := ds.PrepareNewWALFile()
logFile, err := ds.OpenFileForWriting(fm)
if err != nil {
return err
}
d.wal.w = wal.NewWriter(logFile)
d.wal.fm = fm
return nil
}
. . ../db.go
Now, we can make the following modifications to rotateMemtables to pass that metadata to the newly constructed memtable:
. . .
func (d *DB) rotateMemtables() *memtable.Memtable {
d.memtables.mutable = memtable.NewMemtable(memtableSizeLimit, d.wal.fm)
d.memtables.queue = append(d.memtables.queue, d.memtables.mutable)
return d.memtables.mutable
}
. . . ./db.go
Remember that createNewWAL is always called right before rotateMemtables, so d.wal.fm is guaranteed to contain metadata referencing the correct log file.
We can now expose a method that allows us to easily retrieve that data from each memtable:
. . .
func (m *Memtable) LogFile() *storage.FileMetadata {
return m.logMeta
}
. . ../memtable/memtable.go
Our storage provider also needs a new method, allowing it to delete a file based on its supplied metadata:
. . .
func (s *Provider) DeleteFile(meta *FileMetadata) error {
name := s.makeFileName(meta.fileNum, meta.fileType)
path := filepath.Join(s.dataDir, name)
err := os.Remove(path)
if os.IsNotExist(err) {
return nil
}
return err
}
. . ../storage/provider.go
With that, we can finally modify the flush method as follows:
. . .
func (d *DB) flushMemtables() error {
n := len(d.memtables.queue) - 1
flushable := d.memtables.queue[:n]
d.memtables.queue = d.memtables.queue[n:]
for i := 0; i < len(flushable); i++ {
meta := d.dataStorage.PrepareNewSSTFile()
f, err := d.dataStorage.OpenFileForWriting(meta)
if err != nil {
return err
}
w := sstable.NewWriter(f)
err = w.Process(flushable[i])
if err != nil {
return err
}
err = w.Close()
if err != nil {
return err
}
d.sstables = append(d.sstables, meta)
err = d.dataStorage.DeleteFile(flushable[i].LogFile())
if err != nil {
return err
}
}
return nil
}
. . . ./db.go
Now, every time a memtable gets flushed to disk, its corresponding WAL file will be deleted as well.
Replaying WAL Files
At this point, we're successfully writing, rotating, and deleting WAL files, but we don't have a mechanism in place for replaying WAL files from disk in order to reconstruct the memtables lost after a system crash. We should implement this next.
As you remember, when the database restarts, it asks the storage provider to list all the files stored inside the data folder. The storage provider currently only identifies the *.sst files correctly during this process, treating all other file types as unknown, so it's time to modify it to recognize WAL files as well:
. . .
func (s *Provider) ListFiles() ([]*FileMetadata, error) {
files, err := os.ReadDir(s.dataDir)
if err != nil {
return nil, err
}
var meta []*FileMetadata
var fileNumber int
var fileExtension string
for _, f := range files {
_, err = fmt.Sscanf(f.Name(), "%06d.%s", &fileNumber, &fileExtension)
if err != nil {
return nil, err
}
fileType := FileTypeUnknown
switch fileExtension {
case "sst":
fileType = FileTypeSSTable
case "log":
fileType = FileTypeWAL
}
meta = append(meta, &FileMetadata{
fileNum: fileNumber,
fileType: fileType,
})
if fileNumber >= s.fileNum {
s.fileNum = fileNumber
}
}
slices.SortFunc(meta, func(a, b *FileMetadata) int {
return cmp.Compare(a.fileNum, b.fileNum)
})
return meta, nil
}
. . ../storage/provider.go
Now, just like for SSTables, we can add a new field to our main DB structure to store the file metadata of all WAL files found inside the data folder at startup:
. . .
type DB struct {
dataStorage *storage.Provider
memtables struct {
mutable *memtable.Memtable
queue []*memtable.Memtable
}
wal struct {
w *wal.Writer
fm *storage.FileMetadata
}
sstables []*storage.FileMetadata
logs []*storage.FileMetadata
}
. . . ./db.go
After that, we can generalize the loadSSTables method (renaming it to loadFiles) and include logic that populates the newly defined d.logs field with the relevant WAL file metadata:
. . .
func (d *DB) loadFiles() error {
meta, err := d.dataStorage.ListFiles()
if err != nil {
return err
}
for _, f := range meta {
switch {
case f.IsSSTable():
d.sstables = append(d.sstables, f)
case f.IsWAL():
d.logs = append(d.logs, f)
default:
continue
}
}
return nil
}
. . ../db.go
We should refactor the main Open method in our DB structure to make use of the updated method as follows:
. . .
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
if err = db.loadFiles(); err != nil {
return nil, err
}
if err = db.createNewWAL(); err != nil {
return nil, err
}
db.rotateMemtables()
return db, nil
}
. . ../db.go
Next, we introduce an additional couple of methods to encapsulate the logic for reading and replaying the existing WAL files:
. . .
func (d *DB) replayWALs() error {
for _, fm := range d.logs {
if err := d.replayWAL(fm); err != nil {
return err
}
}
d.logs = nil
return nil
}
func (d *DB) replayWAL(fm *storage.FileMetadata) error {
// TODO: implement
}
. . ../db.go
The idea here is have Open call replayWALs right after it loads the WAL file metadata, but before creating a write-ahead log file for the mutable memtable:
. . .
func Open(dirname string) (*DB, error) {
dataStorage, err := storage.NewProvider(dirname)
if err != nil {
return nil, err
}
db := &DB{dataStorage: dataStorage}
if err = db.loadFiles(); err != nil {
return nil, err
}
if err = db.replayWALs(); err != nil {
return nil, err
}
if err = db.createNewWAL(); err != nil {
return nil, err
}
db.rotateMemtables()
return db, nil
}
. . . ./db.go
Underneath, replayWALs forwards each discovered WAL file for processing to the more specialized method replayWAL. We intentionally left replayWAL unimplemented, as we haven't performed any reads from a WAL file thus far.
We'll encapsulate the iteration over records stored inside an existing WAL file into a new structure called a WAL Reader:
. . .
type Reader struct {
file io.Reader
blockNum int
block *block
encoder *encoder.Encoder
}
func NewReader(logFile io.ReadCloser) *Reader {
return &Reader{
file: logFile,
blockNum: -1,
block: &block{},
encoder: encoder.NewEncoder(),
}
}
func (r *Reader) Next() (key []byte, val *encoder.EncodedValue, err error) {
// TODO: implement
}
. . .
./wal/reader.go
The Reader would take a log file open for reading and retrieve records from it, one block at a time. It will use a blockNum field to track the currently loaded block number (-1 meaning "no blocks loaded yet") and a block field to store its actual representation.
An encoder will be used for converting the raw value stored in each WAL record into an EncodedValue that replayWAL can use to determine whether it should insert regular records or tombstones into the memtable. The actual retrieval of records will be performed through repeated calls to the Next method, which will advance the offset pointer of the loaded block, and load additional blocks as necessary.
We can use the Reader to implement the replayWAL method in our DB structure, as follows:
. . .
func (d *DB) replayWAL(fm *storage.FileMetadata) error {
// open WAL file for reading
f, err := d.dataStorage.OpenFileForReading(fm)
if err != nil {
return err
}
// create a new reader for iterating the WAL file
r := wal.NewReader(f)
// prepare a new memtable to apply records to
d.wal.fm = fm
m := d.rotateMemtables()
// start processing records
for {
// fetch next record from WAL file
key, val, err := r.Next()
if err != nil {
if err == io.EOF {
break
}
return err
}
// rotate memtable if it's full
if !m.HasRoomForWrite(key, val.Value()) {
d.rotateMemtables()
}
// apply WAL record to memtable
if val.IsTombstone() {
m.InsertTombstone(key)
} else {
m.Insert(key, val.Value())
}
}
// flush all memtables to disk
d.rotateMemtables()
if err = d.flushMemtables(); err != nil {
return err
}
d.memtables.queue, d.memtables.mutable = nil, nil
// close WAL file
if err = f.Close(); err != nil {
return err
}
return nil
}
. . ../db.go
replayWAL asks the data storage component to open the WAL file for reading and then uses the returned stream to construct a new WAL Reader, while storing the corresponding file metadata into the global d.wal.fm field. It then calls rotateMemtables to prepare a new memtable that the WAL records can be applied to.
The subsequent for loop repeatedly calls Next on the Reader to fetch each record from the WAL file and store it into the memtable using either Insert or InsertTombstone depending on the encoded operation type.
In the unlikely event that the underlying memtable runs out of space, the for loop calls rotateMemtables to create a new memtable for the remaining records. This means that in certain edge cases, you may end up having multiple memtables pointing to the same WAL file. However, this is generally okay, as it's only likely to occur during a replay operation, and memtables used during the replay process are only briefly kept in memory.
Right after the for loop completes (when there are no more WAL records left for processing), another call to rotateMemtables is made to create a new mutable memtable. This is a hacky way of marking all memtables constructed so far from the underlying WAL file as flushable.
Immediately after that, flushMemtables is called to force the data restored from the WAL file into these memtables to be written to disk as SSTables. Effectively, this deletes the WAL file from the system and removes its memtables from main memory.
Next, the remaining mutable memtable is removed, so the storage engine can repeat the entire process cleanly for the next WAL file. As a last step, replayWAL calls Close, thus shutting down the stream associated with the open WAL file.
This repeats for every WAL file discovered at startup.
We can define the following helper method in our Reader to encapsulate the logic for sequentially loading data blocks from a WAL file into memory:
. . .
func (r *Reader) loadNextBlock() (err error) {
b := r.block
b.len, err = io.ReadFull(r.file, b.buf[:])
if err != nil && !errors.Is(err, io.ErrUnexpectedEOF) {
return err
}
b.offset = 0
r.blockNum++
return nil
}
. . ../wal/reader.go
Each subsequent invocation of the loadNextBlock method loads the next 4 KiB from the underlying WAL file into the block buffer. Since the loaded data block may be shorter than the specified blockSize (e.g., if the database crashed, the very last block in the WAL file won't be properly sealed, so its total size will be less than the specified blockSize), we make sure to disregard io.ErrUnexpectedEOF errors and treat them as something expected.
The full implementation of the Next method then goes like this:
. . .
func (r *Reader) Next() (key []byte, val *encoder.EncodedValue, err error) {
b := r.block
// load first WAL block into memory
if r.blockNum == -1 {
if err = r.loadNextBlock(); err != nil {
return
}
}
// check if EOF reached (when last block in WAL is not properly sealed)
if b.offset >= b.len {
err = io.EOF
return
}
start := b.offset
keyLen, n := binary.Uvarint(b.buf[start:])
// check if last record reached (when last block in WAL is properly sealed)
if keyLen == 0 {
if err = r.loadNextBlock(); err != nil {
return
}
start = b.offset
keyLen, n = binary.Uvarint(b.buf[start:])
}
// read next record in WAL block
valLen, m := binary.Uvarint(b.buf[start+n:])
dataLen := int(keyLen) + int(valLen) + n + m
buf := b.buf[start : start+dataLen]
b.offset += dataLen
key = make([]byte, keyLen)
copy(key, buf[n+m:n+m+int(keyLen)])
val = r.encoder.Parse(buf[n+m+int(keyLen):])
return
}
. . ../wal/reader.go
At first, Next checks whether blockNum is -1 to load the very first data block from the underlying WAL file into the block buffer. For non-sealed blocks (i.e., the last block in a WAL file being written to at the time of an abrupt database process termination), it additionally checks whether the block buffer has reached a read offset greater than the block len to prevent any out-of-bounds errors and signal the end of the file.
After these checks pass, Next attempts to read the keyLen of the next WAL record in the block. If keyLen reports 0 , this means that the Reader has reached the zero padded portion of a sealed data block:
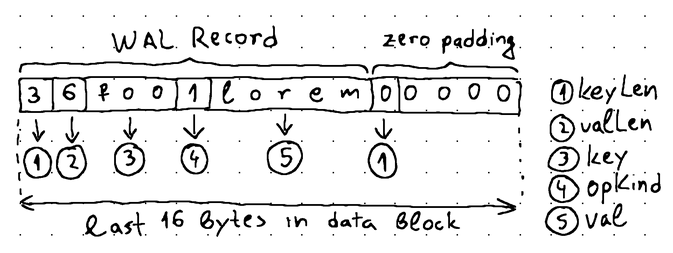
keyLen reports 0 as well.A keyLen equal to 0 signals that the next block should be fetched using loadNextBlock. If, however, keyLen is greater than 0, then Next can continue parsing the record to determine its corresponding key, operation kind (insertion or deletion), and value and return them to the replayWAL method for processing.
With that, you have a fully working Reader implementation and a fully working procedure for replaying WAL files to reconstruct information missing from the memtables of your storage engine.
Chunking WAL Records
Earlier, we mentioned that in most real-world database storage engines, chunking is used as a way to enable DML operations for payloads (i.e., key and val combinations) larger than the specified WAL data block size. This allows for splitting the payload into multiple smaller WAL records (i.e., chunks) that the engine can then easily spread across multiple data blocks within the WAL file.
Chunking is not too difficult to implement but requires some changes to the format of our WAL records. These changes can be expressed like this:
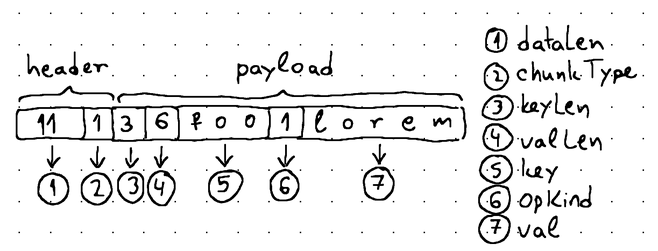
The WAL record now gets an additional header containing 3 bytes of data. The first 2 bytes are allocated for storing the length of the specific payload portion included in this WAL record chunk. Given our 4 KiB data block size, 2 bytes is more than enough to hold values from 1 to 4093 (the smallest and biggest possible payload size within a data block).
The remaining 1 byte is used for storing the chunkType. Here, the chunkType may be:
chunkTypeFullif the chunk contains the entire payload.chunkTypeFirstif the chunk contains only some initial portion of the payload.chunkTypeMiddleif the chunk contains data between the first and last portions of the payload.chunkTypeLastif the chunk contains the remaining portion of the payload.
"Payload" in this context refers to the full representation of a non-chunked WAL record (i.e., its keyLen, valLen, key, opKind, and val all concatenated together).
That being said, we'll no longer store non-chunked records in the write-ahead log. Rather, we'll treat them as chunked records of type chunkTypeFull. As for the other types, they'll only store certain portions of the full payload. These portions can then be concatenated in memory to assemble the full, non-chunked record.
It's important to note that a record split into chunks always has exactly one chunkTypeFirst chunk and one chunkTypeLast chunk. There may be as many additional chunkTypeMiddle chunks in between as necessary (or none at all).
We can start applying changes to our WAL Writer to reflect this information:
. . .
const headerSize = 3
const (
chunkTypeFull = 1
chunkTypeFirst = 2
chunkTypeMiddle = 3
chunkTypeLast = 4
)
. . ../wal/writer.go
Given that payloads can now be of any size, we'll need to incorporate a resizable buffer in our Writer as a staging area for splitting the full payload into chunks that fit into the fixed-size block buffer.
A bytes.Buffer is ideal for that purpose:
. . .
type Writer struct {
block *block
file syncWriteCloser
encoder *encoder.Encoder
buf *bytes.Buffer
}
func NewWriter(logFile syncWriteCloser) *Writer {
w := &Writer{
block: &block{},
file: logFile,
encoder: encoder.NewEncoder(),
buf: &bytes.Buffer{},
}
return w
}
. . ../wal/writer.go
We can then define a new method named scratchBuf to handle the dynamic resizing of the bytes.Buffer based on the length of the incoming payload:
. . .
func (w *Writer) scratchBuf(needed int) []byte {
available := w.buf.Available()
if needed > available {
w.buf.Grow(needed)
}
buf := w.buf.AvailableBuffer()
return buf[:needed]
}
. . ../wal/writer.go
We completely revamp the record method of our Writer to integrate the new WAL record format:
. . .
func (w *Writer) record(key, val []byte) error {
// determine the maximum possible payload length
keyLen, valLen := len(key), len(val)
maxLen := 2*binary.MaxVarintLen64 + keyLen + valLen
// initialize a scratch buffer capable of fitting the entire payload
scratch := w.scratchBuf(maxLen)
// place the entire payload into the scratch buffer
n := binary.PutUvarint(scratch[:], uint64(keyLen))
n += binary.PutUvarint(scratch[n:], uint64(valLen))
copy(scratch[n:], key)
copy(scratch[n+keyLen:], val)
// calculate the actual scratch buffer length being used
dataLen := n + keyLen + valLen
// discard the unused portion
scratch = scratch[:dataLen]
// start splitting the payload into chunks
for chunk := 0; len(scratch) > 0; chunk++ {
// reference the current data block
b := w.block
// seal the block if it doesn't have enough room to accommodate this chunk
if b.offset+headerSize >= blockSize {
if err := w.sealBlock(); err != nil {
return err
}
}
// fill the data block with as much of the available payload as possible
buf := b.buf[b.offset:]
dataLen = copy(buf[headerSize:], scratch)
// write the payload length to the chunk header
binary.LittleEndian.PutUint16(buf, uint16(dataLen))
// advance the scratch buffer and data block offsets
scratch = scratch[dataLen:]
b.offset += dataLen + headerSize
// determine the chunk type and write it to the chunk header
if b.offset < blockSize {
if chunk == 0 {
buf[2] = chunkTypeFull
} else {
buf[2] = chunkTypeLast
}
} else {
if chunk == 0 {
buf[2] = chunkTypeFirst
} else {
buf[2] = chunkTypeMiddle
}
}
// flush updated data block portion to disk
if err := w.writeAndSync(buf[:dataLen+headerSize]); err != nil {
return err
}
}
return nil
}
. . ../wal/writer.go
This may seem daunting at first, but the comments in the code should make it relatively straightforward to understand.
Of course, the Reader needs to change as well. Now that it may be required to reconstruct payloads of any given size in memory, it also needs a scratch buffer to accommodate all of the chunks that comprise the full payload of any given WAL record:
. . .
type Reader struct {
file io.Reader
blockNum int
block *block
encoder *encoder.Encoder
buf *bytes.Buffer
}
func NewReader(logFile io.ReadCloser) *Reader {
return &Reader{
file: logFile,
blockNum: -1,
block: &block{},
encoder: encoder.NewEncoder(),
buf: &bytes.Buffer{},
}
}
. . ../wal/reader.go
The Next method of the Reader then changes in the following way in order to work with the new WAL record format:
func (r *Reader) Next() (key []byte, val *encoder.EncodedValue, err error) {
b := r.block
// load the very first WAL block into memory
if r.blockNum == -1 {
if err = r.loadNextBlock(); err != nil {
return
}
}
// check if EOF reached (when last block in WAL is not properly sealed)
if b.offset >= b.len {
err = io.EOF
return
}
// check if last record in block reached (when last block in WAL is properly sealed)
if b.len-b.offset <= headerSize {
if err = r.loadNextBlock(); err != nil {
return
}
}
// start with a clean scratch buffer
r.buf.Reset()
// recover all chunks to form the full payload
for {
start := b.offset
// extract data from chunk header (payload length and chunk type)
dataLen := int(binary.LittleEndian.Uint16(b.buf[start : start+2]))
chunkType := b.buf[start+2]
// copy recovered payload to scratch buffer
r.buf.Write(b.buf[start+headerSize : start+headerSize+dataLen])
// advance the data block offset
b.offset += headerSize + dataLen
// check if there are no chunks left to process for this record
if chunkType == chunkTypeFull || chunkType == chunkTypeLast {
break
}
// load next block to retrieve the subsequent chunk
if err = r.loadNextBlock(); err != nil {
return
}
}
// retrieve scratch buffer contents (i.e., the payload)
scratch := r.buf.Bytes()
// parse the WAL record
keyLen, n := binary.Uvarint(scratch[:])
_, m := binary.Uvarint(scratch[n:])
key = make([]byte, keyLen)
copy(key, scratch[n+m:n+m+int(keyLen)])
val = r.encoder.Parse(scratch[n+m+int(keyLen):])
return
}./wal/reader.go
Next goes through the WAL file block by block and chunk by chunk to reconstruct the full representation of each record stored inside the write-ahead log and pass it for insertion into a memtable.
With that, we have a fully functional chunking implementation.
Final Thoughts
We've come a long way from where we started, and hopefully you learned a lot about the inner workings of write-ahead logs and their importance in database management systems. Even though the implementation we looked at is a bit simpler than what's used inside a production-grade storage engine, the underlying ideas and concepts remain the same, so you should find it easy to apply this knowledge to understanding more complex systems and implementations.
It's worth mentioning that production-grade storage engines usually delegate the writing of WAL records to a separate thread, and rather than constantly creating and deleting WAL files, they commonly recycle them (i.e., they rename the existing WAL files and gradually overwrite their data).
Furthermore, many production-grade storage engines give you the option of deciding whether WAL files should be synced to disk immediately after every DML operation or whether the syncing can be deferred to a later point in time. This is appropriate when working with less critical data, where you can tolerate some data loss, as it can lead to a significantly higher write throughput.
Lastly, we should mention compression. Many production-grade storage engines provide the option of using compression to reduce the total amount of disk space required for storing WAL files on disk. Of course, this comes at the expense of increased CPU usage, but this trade-off could be worth it depending on the specific use case.
All of this being said, I encourage you to explore these concepts further by looking into the source code of popular storage engines like RocksDB, LevelDB, Pebble, etc. and seeing how they are applied there in practice.
The source code for this tutorial is available at:
 cloudcentricdev
cloudcentricdevThanks for reading and until next time!